题目
Given an array of strings, group anagrams together.
For example, given: ["eat", "tea", "tan", "ate", "nat", "bat"],
Return:
[
["ate", "eat","tea"],
["nat","tan"],
["bat"]
]
排序后生成标准形式
这题考察的就是对标准库的Map和String的使用。
每个单词都先排序,eat变成aet。然后维护一个Map,key值为所有出现过的像aet这样的排序后的标准表达,value值为在List<List<String>>中对应的List的id。
代码
public class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
List<List<String>> res = new ArrayList<>();
Map<String,Integer> dic = new HashMap<>();
for (int i = 0; i < strs.length; i++) {
char[] chars = strs[i].toCharArray();
Arrays.sort(chars);
String str = new String(chars);
Integer pos = dic.get(str);
if (pos == null) { // new group
dic.put(str,dic.size());
res.add(new ArrayList<String>(Arrays.asList(new String[]{strs[i]})));
} else { // already exist
res.get(pos).add(strs[i]);
}
}
return res;
}
}
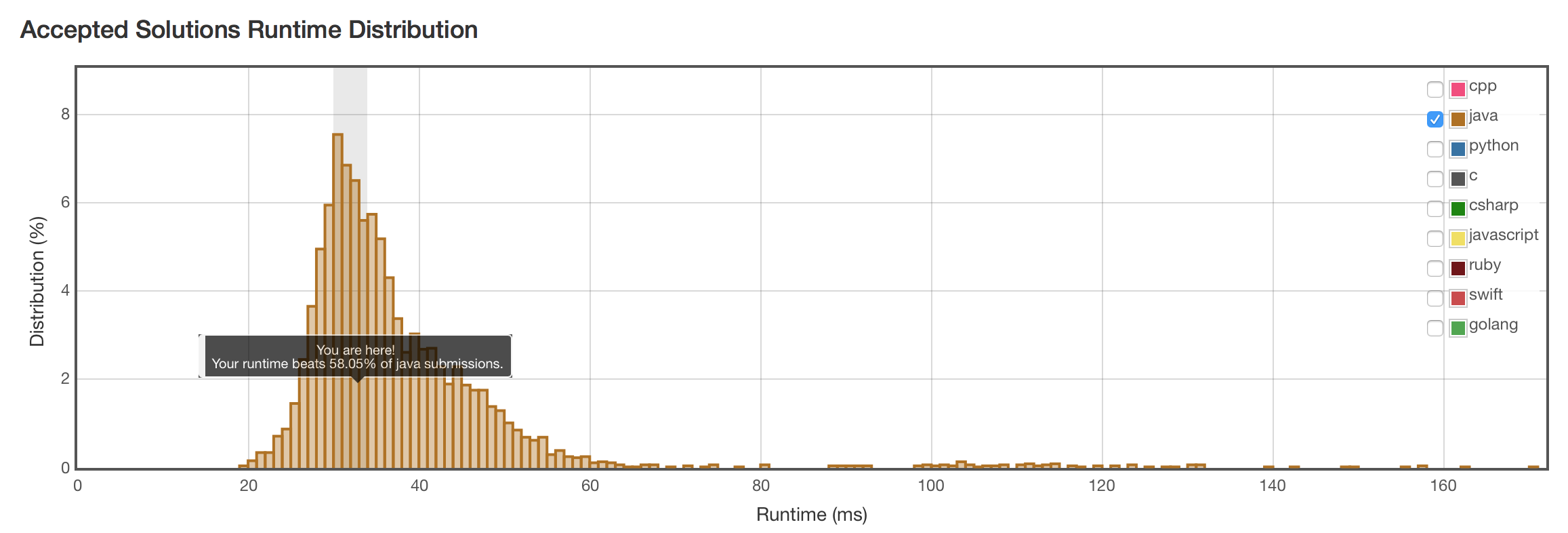
结果
没什么花样,银弹!
自建哈希值比对
发现一个有意思的方法,不是我首创。就是利用一组26个素数,映射到26个字母。然后每个单词计算每个字母对应的素数的成绩。比如我们的素数如下,
int[] prime = new int[]{2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103};
eat的e,a,t分别对应:11,2,71。所以所有以这三个字母组成的单词,最后得到的id都是:11*2*71=1562。利用这个id,就可以判断是不是相同字母组成的单词。
代码
public class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
List<List<String>> res = new ArrayList<>();
Map<Long,Integer> dic = new HashMap<>();
// 对应26个字母
int[] prime = new int[]{2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103};
for (int i = 0; i < strs.length; i++) {
char[] chars = strs[i].toCharArray();
long key = 1;
for (char c : chars) {
key *= prime[c-'a'];
}
Integer pos = dic.get(key);
if (pos == null) { // new group
dic.put(key,dic.size());
res.add(new ArrayList<String>(Arrays.asList(new String[]{strs[i]})));
} else { // already exist
res.get(pos).add(strs[i]);
}
}
return res;
}
}
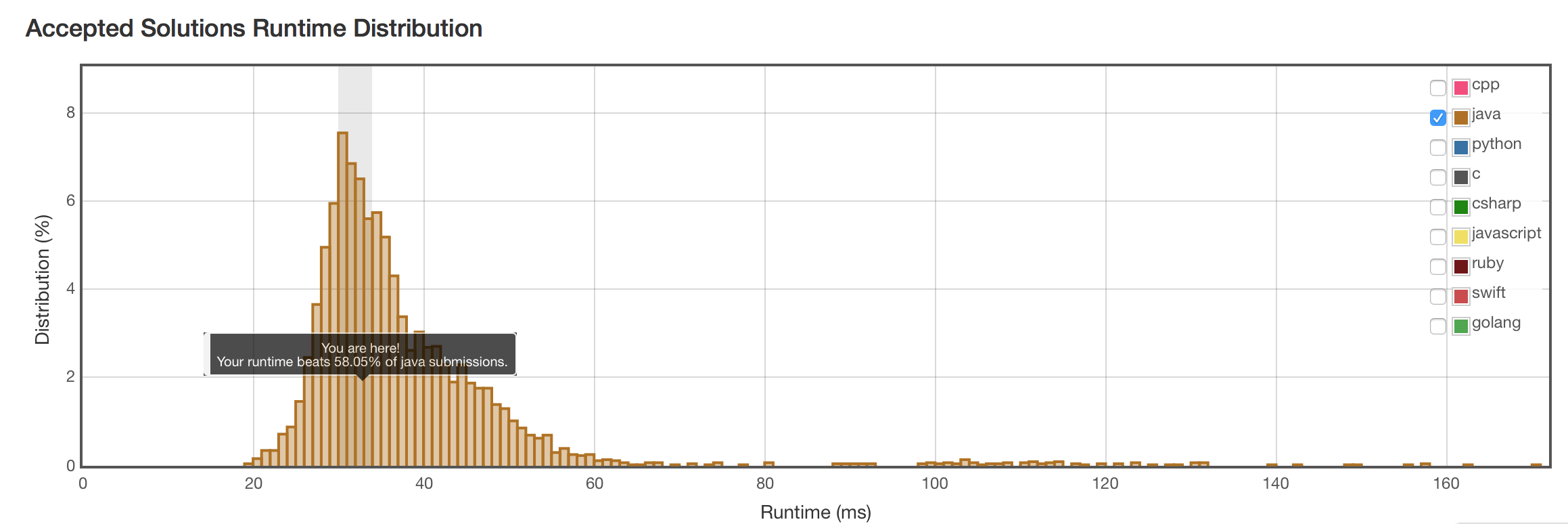
结果
速度差不多。