摘要
这章讲平时最常用的String字符串。主要讲了一下几件事:
- String的内部结构和特性
- 更高效的字符串构造工具StringBuilder
- 标准化输出“format”
- 正则表达式
- 正则表达式的应用Pattern和Matcher以及Scanner
String
String看似常用,其实越简单的东西往往越靠近底层。有很多隐藏起来的复杂性并没有被我们看到。
String到底是个什么?
翻开JDK中String的源码第一段:
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
/** String本质是个char数组. */
private final char value[];
...
...
}
这告诉我们,String的本质是一个char[]字符数组。
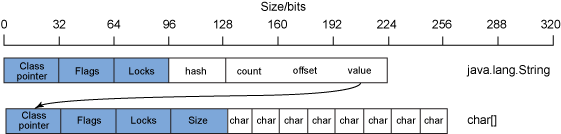 如上图所示,一个String由两部分组成:存放信息实体的字符数组char[]和管理这个char[]的元信息。我们以一个32位系统上含有8个字符的String为例,每个char32位,char[]纯信息一共128位。用来管理Array的元信息128位。所以整个char[]一共256位。另外String用来管理char[]的元信息一共244位。所以加在一起一共480位(60个字节)用来表示128位(16个字节,或者说8个字符)。
如上图所示,一个String由两部分组成:存放信息实体的字符数组char[]和管理这个char[]的元信息。我们以一个32位系统上含有8个字符的String为例,每个char32位,char[]纯信息一共128位。用来管理Array的元信息128位。所以整个char[]一共256位。另外String用来管理char[]的元信息一共244位。所以加在一起一共480位(60个字节)用来表示128位(16个字节,或者说8个字符)。
其中,String的三大元数据分别是,
- hash:是用来记录已经计算好的本String的散列值。避免重复计算。初始值为零。
- count:是记录String的长度。也就是char[]的长度。
- offset:偏移值。顾名思义,用来在substring()取子字符串的时候标明偏移值。
作为程序员在用数据的时候,起码要知道自己手上用的是个什么东西。
String是不可变的,线程安全的
关于String两个最基本的特性要记住,第一,String是不可变的。第二,String是线程安全的。
什么是不可变?
String不可变很简单,如下图,给一个已有String第二次赋值,不是在原内存地址上修改数据,而是重新指向一个新对象,新地址。
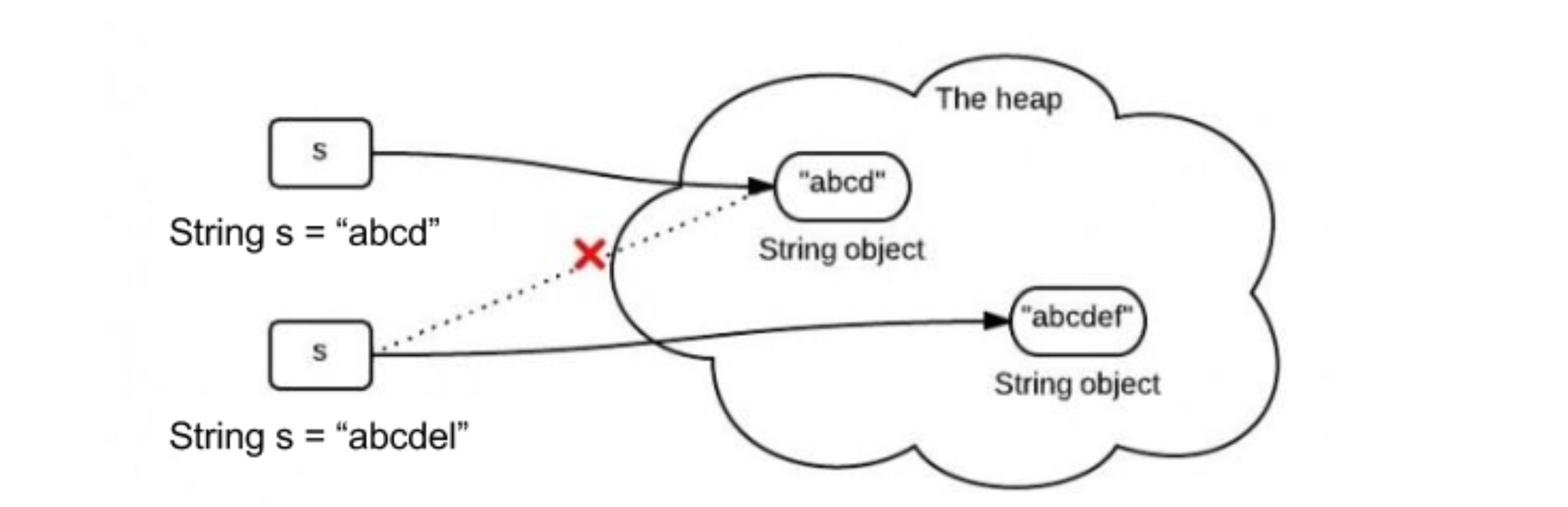
为什么String是不可变的?
首先String类是用final关键字修饰,这说明String不可继承。再看下面,String类的主力成员字段 value 是个 char[ ] 数组,而且是用final修饰的。final修饰的字段创建以后就不可改变。有的人以为故事就这样完了,其实没有。因为虽然value是不可变,也只是value这个引用地址不可变。挡不住Array数组是可变的事实。Array的数据结构看下图,
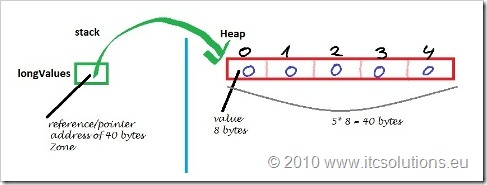 也就是说Array变量只是stack上的一个引用,数组的本体结构在heap堆。String类里的value用final修饰,只是说stack里的这个叫value的引用地址不可变。没有说堆里array本身数据不可变。看下面这个例子,
也就是说Array变量只是stack上的一个引用,数组的本体结构在heap堆。String类里的value用final修饰,只是说stack里的这个叫value的引用地址不可变。没有说堆里array本身数据不可变。看下面这个例子,
final int[] value={1,2,3}
int[] another={4,5,6};
value=another; //编译器报错,final不可变
value用final修饰,编译器不允许我把value指向堆区另一个地址。但如果我直接对数组元素动手,分分钟搞定。
final int[] value={1,2,3};
value[2]=100; //这时候数组里已经是{1,2,100}
所以String是不可变,关键是因为SUN公司的工程师,在后面所有String的方法里很小心的没有去动Array里的元素,没有暴露内部成员字段。而且还很小心地把整个String设成final禁止继承,避免被其他人破坏。所以String是不可变的关键都在底层的实现,而不是一个final。考验的是工程师构造数据类型,封装数据的功力。
不可变有什么好处?
这个最简单地原因,就是为了安全。看下面这个场景(有评论反应例子不够清楚,现在完整地写出来),一个函数appendStr( )在不可变的String参数后面加上一段“bbb”后返回。appendSb( )负责在可变的StringBuilder后面加“bbb”。
class Test{
//不可变的String
public static String appendStr(String s){
s+="bbb";
return s;
}
//可变的StringBuilder
public static StringBuilder appendSb(StringBuilder sb){
return sb.append("bbb");
}
public static void main(String[] args){
//String做参数
String s=new String("aaa");
String ns=Test.appendStr(s);
System.out.println("String aaa >>> "+s.toString());
//StringBuilder做参数
StringBuilder sb=new StringBuilder("aaa");
StringBuilder nsb=Test.appendSb(sb);
System.out.println("StringBuilder aaa >>> "+sb.toString());
}
}
//Output:
//String aaa >>> aaa
//StringBuilder aaa >>> aaabbb
如果程序员不小心像上面例子里,直接在传进来的参数上加”bbb”,因为Java对象参数传的是引用,所以可变的的StringBuffer参数就被改变了。可以看到变量sb在Test.appendSb(sb)操作之后,就变成了”aaabbb”。有的时候这可能不是程序员的本意。所以String不可变的安全性就体现在这里。
再看下面这个HashSet用StringBuilder做元素的场景,问题就更严重了,而且更隐蔽。
class Test{
public static void main(String[] args){
HashSet<StringBuilder> hs=new HashSet<StringBuilder>();
StringBuilder sb1=new StringBuilder("aaa");
StringBuilder sb2=new StringBuilder("aaabbb");
hs.add(sb1);
hs.add(sb2); //这时候HashSet里是{"aaa","aaabbb"}
StringBuilder sb3=sb1;
sb3.append("bbb"); //这时候HashSet里是{"aaabbb","aaabbb"}
System.out.println(hs);
}
}
//Output:
//[aaabbb, aaabbb]
StringBuilder型变量sb1和sb2分别指向了堆内的字面量”aaa”和”aaabbb”。把他们都插入一个HashSet。到这一步没问题。但如果后面我把变量sb3也指向sb1的地址,再改变sb3的值,因为StringBuilder没有不可变性的保护,sb3直接在原先”aaa”的地址上改。导致sb1的值也变了。这时候,HashSet上就出现了两个相等的键值”aaabbb”。破坏了HashSet键值的唯一性。所以千万不要用可变类型做HashMap和HashSet键值。
还有一个大家都知道,就是在并发场景下,多个线程同时读一个资源,是不会引发竟态条件的。只有对资源做写操作才有危险。不可变对象不能被写,所以线程安全。
最后别忘了String另外一个字符串常量池的属性。接下来正好要讲这个。Java之所以能实现这个特性,String的不可变性是最基本的一个必要条件。要是内存里字符串内容能改来改去,这么做就完全没有意义了。
String常量池
由于String是Java里最常用的数据类型之一,往往内存里会塞满了String,而且互相重复,数据冗余很高。为了避免内存臃肿,提高效率,java实现了一套基于 字符串常量池的优化方案。
用String Table驻留一个String对象的引用,每次要用到一个String字面量的时候,都会先查这个表。确定没有再创建,有的话就直接复制一个驻留引用。 String Table在哪儿? 可以理解为过去说的Perm Generation 永生代里,方法区的外面。 原理这里不展开了,详细可以参看一篇专题:《String str=new String(“Hello”)到底创建了几个对象?》。
这里我就贴一个简单的结论,方便以后查阅。更详细的例子,和解释都在上面这篇专题里。
class Test {
private static String staticStr="Hello";
private String memberStr="Hello";
public void sayHello(){
String methodStr="Hello";
System.out.println(methodStr);
}
public static void main (String[] args) {
Test t=new Test();
t.sayHello();
String threadStr="Hello";
}
}
代码中,staticStr是Test类的静态成员变量,memberStr是普通成员变量。methodStr是sayHello方法的局部变量。在主线程方法main里,还有一个threadStr。
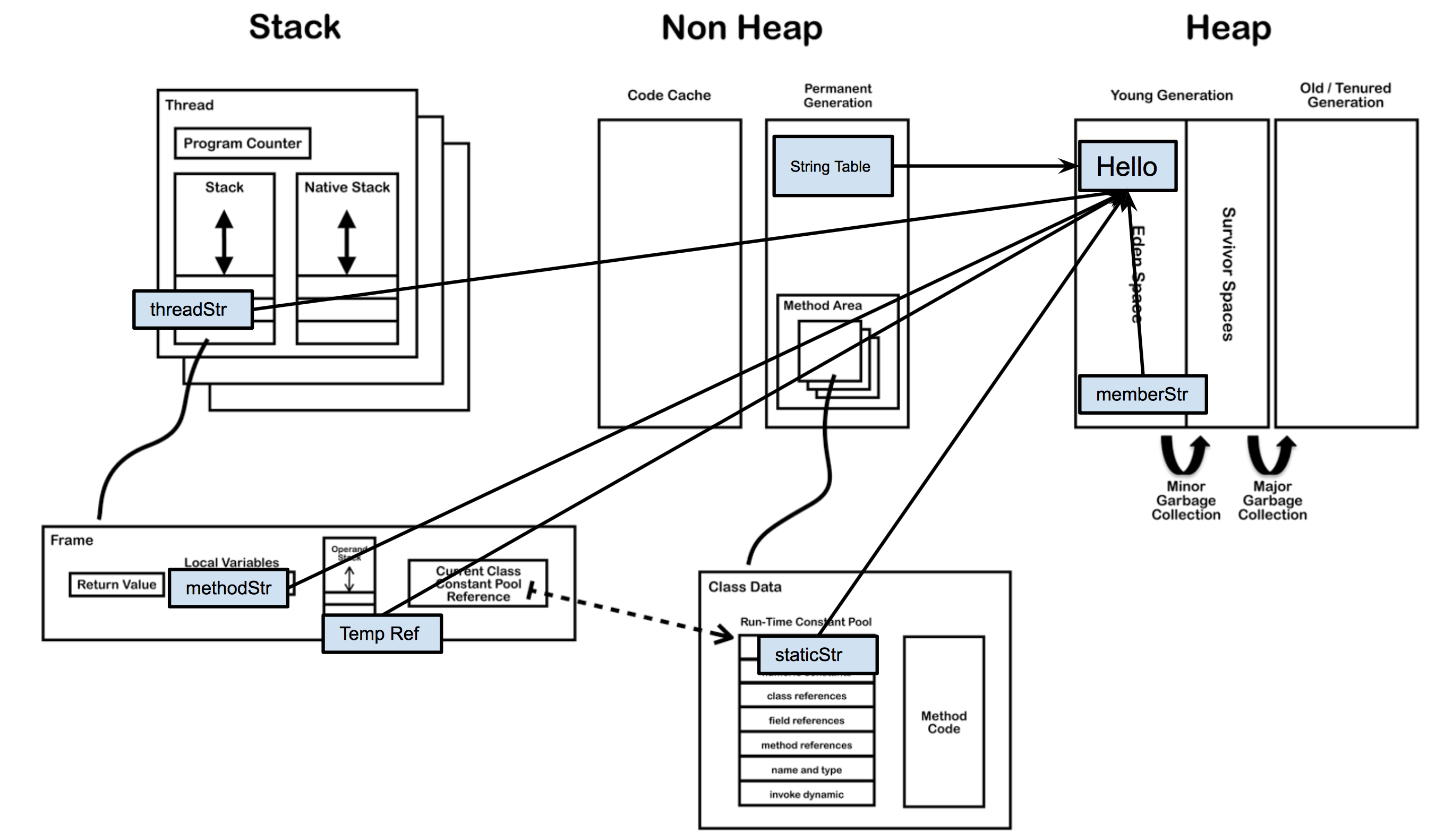 如上图所示,四个变量都指向堆区新生代里的同一个对象实例“Hello”。但程序运行过程里,内存里实际存在过6个对这个对象的引用。具体如下,
如上图所示,四个变量都指向堆区新生代里的同一个对象实例“Hello”。但程序运行过程里,内存里实际存在过6个对这个对象的引用。具体如下,
- 首先方法区外面的字符串常量池有一个长期驻留引用。
- 第二,静态变量staticStr,理论上可以认为存在方法区的运行时常量池里。但就像您文章里测出来实际是在堆里,是因为不同JVM具体操作不同。
- 第三,memberStr是作为Test类的成员变量,存在堆里。
- 第四,methodStr变量存在栈区sayHello()方法的私有栈帧里的局部变量表。
- 第五,我们用System.out打印变量methodStr的时候,会有一个新的对“Hello”的引用被压到操作数栈里。但很快操作完就又弹出去了。
- sayHello()函数运行完methodStr变量对“Hello”对象的引用就被释放。
- 第六个,主线程main里的threadStr变量也存在一个栈帧的局部变量表里。
- 最后程序运行完,除了字符串常量池里的驻留引用还继续生存,其他引用全部被释放。
不可变特性影响了String的效率
String不可变的特性,影响了它的效率。比如“+”拼接字符串,因为String不可变,不可以直接在原字符串后面拼接,每次都需要重建一个新对象,来存放拼接后更长的字符串。拼接多次,中间生成的字符串就会成为垃圾,需要被回收。我们知道java的垃圾回收开销又很大。比如下面最简单的操作,
String str="a"+"b"+"c"+"d"+"e";
如果用笨办法拼接,最后为了得到“abcde”,java堆会产生”a”,”b”,”c”,”d”,”e”,”ab”,”abc”,”abcd”这么多中间对象,再算上垃圾回收的时间,真的会很慢。
更高效的字符串构造工具StringBuilder
Java为了优化性能,设计了一个StringBuilder类,它是可变的。使得StringBuilder.append()方法拼接字符串,是直接在原字符串上拼接。不产生中间字符串,提高了效率。
那StringBuilder.append()是怎么做到不产生中间副产品字符串的呢?
因为StringBuilder是可变的。直接看源码,StringBuilder的基类AbstractStringBuilder数据容器char数组不是final的:
char[] value;
AbstractStringBuilder#append()方法直接调用String#getChars()。
// Documentation in subclasses because of synchro difference
public AbstractStringBuilder append(StringBuffer sb) {
if (sb == null)
return append("null");
int len = sb.length();
ensureCapacityInternal(count + len);
sb.getChars(0, len, value, count);
count += len;
return this;
}
而String#getChars()直接调用的是System.arrayCopy():
public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) {
if (srcBegin < 0) {
throw new StringIndexOutOfBoundsException(srcBegin);
}
if (srcEnd > value.length) {
throw new StringIndexOutOfBoundsException(srcEnd);
}
if (srcBegin > srcEnd) {
throw new StringIndexOutOfBoundsException(srcEnd - srcBegin);
}
System.arraycopy(value, srcBegin, dst, dstBegin, srcEnd - srcBegin);
}
而System.arrayCopy()是一个本地方法,用Native关键字修饰。说明它的实现是调用本地系统的用C或者C++写的程序执行字符串的拼接。为了更高的效率。
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
这个底层的arraycopy就先不管,只要知道它是一个效率比较高的直接拼接数组的函数就可以了。
简单的String拼接真的这么慢吗?
再回到String,还是开始的简单例子,”a”+”b”+”c”+”d”。实际我们执行下面的语句真的很慢吗?
//String直接字面拼接:1308纳秒
String result="a"+"b"+"c"+"d";
//StringBuilder拼接:42920纳秒
StringBuilder sb=new StringBuilder();
sb.append("a");
sb.append("b");
sb.append("c");
sb.append("d");
//String对象拼接:13774纳秒
String a=new String("a");
String b=new String("b");
String c=new String("c");
String d=new String("d");
String str=a+b+c+d;
简单做个上面这个测试,结果是String字面量直接拼接耗时1308纳秒,而StringBuilder耗时为42920纳秒,String对象拼接:13774纳秒。
所以,真相是String类像这样简单地字面量的拼接操作也已经被优化过了,String result=”a”+”b”+”c”+”d”基本可以等同于String result=”abcd”。而且创建StringBuilder实例本身的开销也不小,区区几个字符的拼接,还体现不出它的价值,甚至还不够弥补它本身实例化的开销。
那什么规模能体现出StringBuilder的优势呢? 下面我们把上面每个操作都重复了一万次。
//String直接字面拼接:105334355纳秒
String a="a";
String b="";
for(int i=0;i<10000;i++){
b+=a;
}
//StringBuilder拼接:415360纳秒
StringBuilder sb=new StringBuilder();
for(int i=0;i<10000;i++){
sb.append("a");
}
//String对象拼接:198404867纳秒
String s=new String("");
for(int i=0;i<10000;i++){
String x=new String("a");
s+=x;
}
再看结果:
- String直接字面拼接: 105334355 纳秒
- StringBuilder拼接: 415360 纳秒
- String对象拼接: 198404867 纳秒
是不是StringBuilder的优势出来了?快了1000倍。为什么呢?因为由于for的循环结构,String拼接只能老老实实每次创建一个新对象了。JVM内部”+“加号操作符的红利就没有了。
所以,要记住下面这个结论:
简单的个别几个字符串拼接,还是用String直接拼接更快。如果有大量的字符串需要拼接,并且用到了loop循环控制流,这时候就是StringBuilder效率更高了。
循环的时候,注意手动在循环外创建一个StringBuilder
刚才实验也显示了,StringBuilder实例化的开销比单个String对象的创建开销大多了。所以用循环语句拼接的时候,注意要在循环域外先创建一个StringBuilder,否则每次循环都会创建一个新的StringBuilder。
下面这个代码,
String s=new String();
for(int i=0;i<10;i++>){
s+=i;
}
相当于以下操作,
String s=new String();
for(int i=0;i<10;i++>){
StringBuilder sb=new StringBuilder();
sb.append(i);
}
这种循环拼接字符串的情况,还是手动在循环外面创建一个StringBuilder比较好,
StringBuilder sb=new StringBuilder();
for(int i=0;i<10;i++>){
sb.append(i);
}
String V.s. StringBuilder V.s. StringBuffer
有了String和StringBuilder,为什么还要StringBuffer呢?
其实是人家StringBuffer先出来的好吗。StringBuilder是在Java1.5才加进来的。
String 不可变 (线程安全) since JDK1.0 java.lang.String public final class String
StringBuffer 可变(线程安全) since JDK1.0 java.lang.StringBuffer public final class StringBuffer
StringBuilder 可变(非线程安全)since JDK1.5 java.lang.StringBuilder public final class StringBuilder
关于StringBuffer,这里就先不贴源码了,需要记住的点是:
- StringBuffer和StringBuilder一样是可变的。大规模拼接效率高于String。
- 相较于StringBuilder的线程不安全,StringBuffer是线程安全的。多用于并发编程的场景。
- 线程安全是要有内存和效率上的代价的。具体是加锁的开销。
归纳成一句,就是StringBuffer和StringBuilder一样都是String的辅助类。但StringBuilder是适用于单线程的轻量级版,StringBuffer是用于并发场景的重量级版。
最后贴一个StringBuilder和StringBuffer直接的PK。
//StringBuilder拼接:415360纳秒
StringBuilder sb=new StringBuilder();
for(int i=0;i<10000;i++){
sb.append("a");
}
//StringBuilder拼接:810470纳秒
StringBuffer sbf=new StringBuffer();
for(int i=0;i<10000;i++){
sbf.append("a");
}
测试结果:
- StringBuilder拼接: 415360 纳秒
- StringBuffer拼接: 810470 纳秒
StringBuilder比StringBuffer快了近一倍。
格式化输出
格式化输出,这个功能还是会很实用的。内存终归是有限的,实际工作中大量的数据是记录在外部文件里的,在学校的时候,经常跑一个实验就用到几百个G,甚至几个TB的样本数据。所以格式化输出的意义不是看打印出来漂不漂亮,而是在于让储存在外部文件里的数据更适于批量处理和读写。
Java里有三个类提供了格式化输出功能,也就是format()方法。他们都接受相同的参数来格式化输出。
- 第一个:System.out.format()和System.out.printf()。这两个是等价的。
- 第二个:Formatter#format()。
- 第三个:String#format()。接受的参数和前两个一样。不同是会返回格式化的String型。但这个方法的好处是,它是String的静态方法,不用创建实例,比较方便。打印规模小的可以考虑用这个。
格式化语法
一般在控制台输出点东西,这样简单的使用场景,会写这样的格式:
System.out.println("Row 1: ["+x+" "+y+" "+z+"]\n");
System.out.printf("Row 1: [%d %f %s]\n", x, y, z);
System.out.format("Row 1: [%d %f %s]\n", x, y, z);
这里,%d和%f和%s叫占位符,表示x插入%d的位置,y插入%f的位置,z插入%s的位置。%d表示数据转换成整型输出,%f表示数据转换成浮点型,%s表示数据转换成String型。
但这只是很简单的使用场景,虽然能用,但功能有限。完整的格式化语法是下面这个样子:
(%[argument_index$][flags][width][.precision][conversion], arg1, arg2, arg3, …)
其中每个位置分别表示:
- argument_index: 一个正整数。标明是第几个参数。“1$”表示第一个参数arg1, “2$”表示第二个参数arg2,以此类推。
- flags: 格式符。比较常用的几个是:”-“表示左对齐。” “空格表示右对齐,前面用空格填满。”0”右对齐,前面用0填满。
- width: 一个正整数。表示这个域的最小尺寸。不足用空格来补。
- precision: 精度。对不同数据类型的意义不同。对String表示字符串的最大长度。对float和double则表示小数部分有几位。
- conversion: 转换成什么数据类型来输出。之前的%d这样的占位符,其实就是中间其他参数省略的结果,最后的conversion直接跟在%后面。
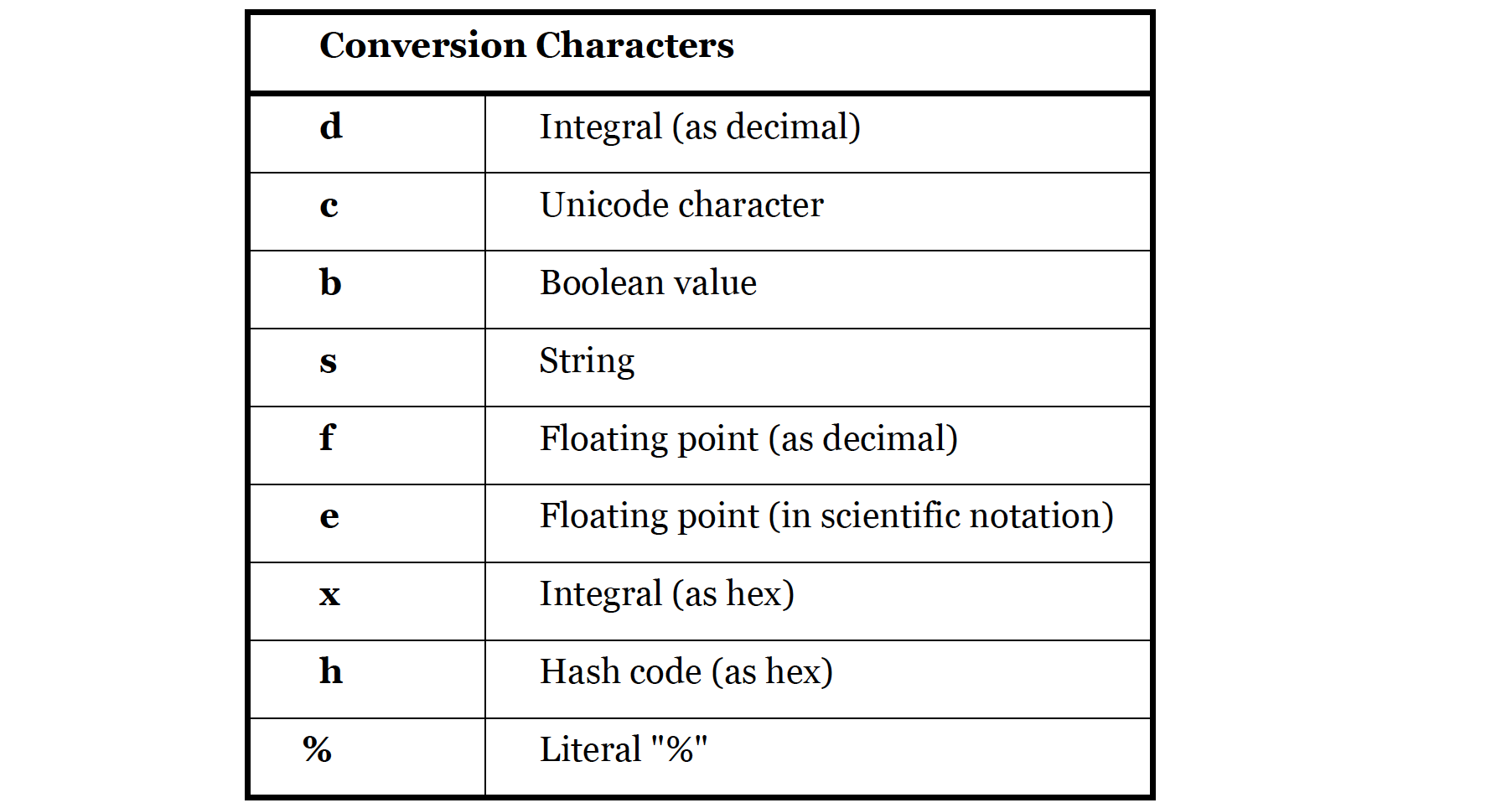
下图是常用的flags格式符
 下图是常用的conversion数据类型
下图是常用的conversion数据类型
小练习:发票
下面用一个例子实际演示怎么使用格式化语法。下面代码用于打出和书上一样的小发票。
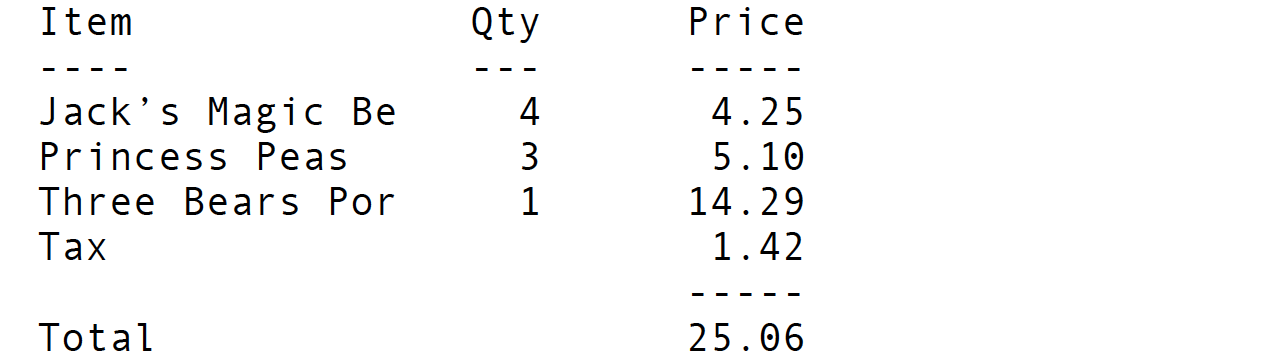
代码里用的是Formatter#format(),其实无论换成System.out.format()或者System.out.printf(),再或者String#format()效果都是一样的。下面是代码:
class Receipt {
/**
* PUBLIC METHODS
*/
public void printTitle(){
f.format("%1$-20.15s %2$3.3s %3$10.10s\n","Item","Qty","Price");
f.format("%1$-20.15s %2$3.3s %3$10.10s\n","----","---","-----");
}
public void print(String name, int qty, double price){
f.format("%1$-20.15s %2$3d %3$10.2f\n",name,qty,price);
total+=price;
}
public void printTotal(){
f.format("%1$-20.15s %2$3s %3$10.2f\n","Tax", "", total*0.15);
f.format("%1$-20.15s %2$3s %3$10.10s\n","", "","-----");
f.format("%1$-20.15s %2$3s %3$10.2f\n","Total", "",total*1.15);
}
/**
* PRIVATE FIELDS
*/
private double total=0;
private Formatter f=new Formatter(System.out);
/**
* MAIN
*/
public static void main(String[] args){
Receipt r=new Receipt();
r.printTitle();
r.print("Jack’s Magic Beans", 4, 4.25);
r.print("Princess Peas", 3, 5.1);
r.print("Three Bears Porridge", 1, 14.29);
r.printTotal();
}
}
简单举例解释“%1$-20.15s”这一段中:
- ”%”: 开头。 告诉编译器下面这段是格式语句。
- “1$”: [argument_index$]。 表示使用后面三个参数中的第一个。
- ”-“: [flags]。表示不用默认的右对齐,而是左对齐。
- “20”: [width]。表示这段长度保持为20。不够用空格补满。
- “.15”: [.precision]。表示String的长度最多为15,超过的不打印。
- ”s”: [conversion]。表示数据是String型。
打印出来的效果就和上面书上的小发票的图一模一样。
正则表达式
最后是这一章的一个大头,正则表达式。有多重要呢?如果不牢牢掌握的话,都不好意思说自己是程序员吧?写正则表达式,同一个意思可以有很多种写法,需要掌握一个原则:不是要写最花哨的表达式,而是写最简单,最好理解的表达式,只要足够完成任务就行。
语法
语法因为比较复杂,这里不可能完整地复制过来。只挑比较重要的列出来。完整的语法定义参见“java.util.regex.Pattern”类的官方文档。里面有最权威的描述。再想深入学,可以读Friedl的《精通正则表达式-第3版》。
正则表达式最常用到的符号就是三个表示数量的符号了:
- ?: 一段字符,出现零次或一次。
- *: 一段字符,出现零次或一次或多次。就是不管出现不出现,也不管出现多少次。
- +: 一段字符,至少出现一次或多次。就是出现至少一次。
- {n}: 一段字符,准确地出现n次。
- {n,}: 一段字符,至少出现n次。
- {n,m}: 一段字符,至少出现n次,但至最多出现m次。
这些表示数量的符号要结合表示“字符”的符号一起使用。正则表达式语法里定义了很多,举几个最常用的例子:
- 1: 正常阿拉伯数字,就表示它本身。
- x: 正常英语字母,就表示他们本身。
- .: 任意字符
- \d: 任意一个[0-9]的阿拉伯数字。
- \D: 除了[0-9]数字之外的其他所有字符。
- \s: 一个空白符。包括[ \t\n\x0B\f\r]这些。这个真的很好用。
- \S: 相反的除了空白符之外的所有字符。
- \w: 一个单词字符。就是英语大小写字母加阿拉伯数字零到九,注意还有一个下划线
_也算在里面。[a-zA-Z_0-9] - \W: 除了单词字符以外的全部其他字符。
- \b: 单词边界符。这比较神奇。只匹配一个单词的边界,不匹配任何字符。占零个长度。这里的单词,就是前面\w单词符的内容。
- \B: 判断不是单词边界。
还有其他的一些格式符:
- \t: 一个tab符。对应的ASKII码是:(‘\u0009’)
- \n: 一个换行符。对应的ASKII码是:(‘\u000A’)
- \r: 一个回车符。对应的ASKII码是:(‘\u000D’)
- \e: 一个空格符。对应的ASKII码是:(‘\u001B’)
- ^: 行首符。必须在正则表达式的起始位置。
- $: 行尾符。也可以是文末符,表示一段文本的末尾。
注意这里的一个 反斜杠”" 是很重要的,代表一个 “转义符”。因为后面的那些字母都有它们自身的意义,前面加个反斜杠转义符,就是说:不表示他们的常规意义了,现在开始表示它的特殊意义。就是这样。但如果用在想一个点(或者说是句号)”.” 的前面,因为这个点”.”本身不代表一个“句号”,而是是代表任意字符,已经转意了,前面再加一个转义符,就是转回来表示它的字面意义:“一个句号”。
- .: 需要转义,才代表一个“点”。
- \: 也需要转个义,两个反斜杠才是真的表示一个反斜杠。
另外,方括号 “[]” 代表一个“或”集。代表里面的字符,任取其一
- [abc]: a或b或c。
- [^abc]: 除了a,b,c之外的任意其他字符。这里”^”在括号里就是“异”符号。在正则表达式的开头就表示行首符。
括号 ”()” 和数学公式里一样,表示优先合并。每个用括号扩起来的都是一个“组”。这个在的Matcher#group()方法会用到,它专门返回正则表达式的第几个组。
转义符
转义符看上去很简单,两种情况:
- 正常字符转成不正常字符:比如”\n”换行符,”\t”Tab符,”\r”回车符,”\0”空格符。
- 特殊字符转回成正常意义:比如”'“单引号,”"“双引号。
但还是要专门提一下。自己以前经常被坑。
首先单纯从正则表达式的角度讲,”.“ 表示一个“句号”。两个反斜杠 ”\“ 表示一个正常反斜杠。都很好理解。
但在Java里,真的要用字符串表示一个句号”.”,要用 ”\.”。反斜杠”",要用 ”\\“ 来表示。吃过很多次亏。
这到底是为什么呢?简单讲是因为:正巧Java语言里,反斜杠 ”" 也是作为转义符存在,而我们在.java文件里的一个字符串String在被理解成正则表达式之前,要经过Java编译器,和正则表达式编译器的两次翻译。
第一次翻译:Java编译器。
对Java编译器来讲,单个反斜杠”"是个特殊字符。和正则表达式里一样,也是“转义符”。是用来转义其他所有特殊字符。悲剧由此开始。
所以要让Java编译器认出一个正常意义的反斜杠,就需要转义他自己:”\“两个反斜杠表示这是一个反斜杠。
第二次翻译:正则表达式编译器。
经过java编译器翻译的内容,会交到正则编译器手里。不幸在这里反斜杠又是转义符,要让要想让正则表达式编译器读出一个反斜杠,要对正则编译器说”\“。
那怎么才能把两个反斜杠”\“交到正则编译器手里呢?
对了,就要交给java编译器四个反斜杠”\\“,翻译成两个反斜杠”\“之后交到正则编译器手里,再第二次翻译成一个反斜杠”"。
这叫什么?这就是贪污啊。把反斜杠看成是金条。我要是想交给正则表达式匹配函数一根金条,就要交给java编译器四根金条,贪污掉一半,剩两条交给正则表达式编译器,再贪污掉一半,最后剩的这根才交到表达式函数手里。
对一个句号”.”也是一样,”\.”给Java编译器,贪污一个反斜杠以后,交到正则编译器手里的时候剩一个反斜杠:”.“。然后正则编译器再贪污一遍,翻译成了”.”。
正则表达式的应用
Java里使用正则表达式,主要通过两个地方:
- 第一,String对象的很多方法就能直接用。
- 第二,java.util.regex包里的Pattern类和Matcher类配合起来使用,功能更强大。
String对象使用正则表达式
String里用正则表达式的方法有常用的 matches(String regex), 替换 replaceFirst(String regex, String replacement), replaceAll(String regex, String replacement),切割 split(String regex)。参数里的regex就代表着这个参数接受Sting形式的正则表达式。比如像下面这个例子,可以直接拿字符串去和一个正则表达式匹配。
"hello world".match("(?i)((^[aeiou])|(\\s+[aeiou]))\\w+?[aeiou]\\b")
//output: false
上面例子里的正则表达式,翻译成人话就是:一个以元音(aeiou)开头,元音结尾的单词。其中(?i)表示一种匹配策略CASE_INSENSITIVE,忽略所有大小写。在Pattern和Matcher类里也有这个功能。然后明显hello和word都不是元音开头,所以返回false。
Pattern & Matcher
另外,在java.util.regex包里的 Pattern 类和 Matcher 类才是专门为正则表达式而生的类。
用法也很简单,Pattern.compile(String regex)方法可以把String形式的正则表达式编译成一个Pattern对象。然后Pattern#matcher(String str)方法通过给Pattern对象传递一个需要匹配的字符串,返回一个Matcher对象。可以调用Matcher类的各种方法,比如Matcher#split()以及Matcher#replaceAll()。
Matcher#find( )
public boolean Matcher#find()尝试查找与该模式匹配的输入序列的下一个子序列。此方法从匹配器区域的开头开始,如果该方法的前一次调用成功了并且从那时开始匹配器没有被重置,则从以前匹配操作没有匹配的第一个字符开始。如果匹配成功,则可以通过 start、end 和 group 方法获取更多信息。
- matcher.start() 返回匹配到的子字符串在字符串中的索引位置.
- matcher.end()返回匹配到的子字符串的最后一个字符在字符串中的索引位置.
- matcher.group()返回匹配到的子字符串
当且仅当输入序列的子序列匹配此匹配器的模式时才返回 true。
Matcher#matches( )
public boolean Matcher#matches()尝试对整个目标字符串进行正则匹配,只有当整个字符串完整匹配,才返回true。
而且,在Pattern类里有一个相同功能的静态方法Pattern.matches()。不用创建Pattern和Matcher对象适合小规模零散正则匹配。如果要多次使用一种模式,编译一次生成Pattern对象,重用此模式比每次都调用此方法效率更高。
public static boolean matches(String regex, CharSequence input)
//使用
Pattern.matches(regex, input);
Matcher#lookingAt( )
和find()和matches()方法类似,也是匹配目标字符串和正则表达式。不同点是lookingAt()是从目标字符串的开头开始找有没有能匹配正则表达式的一个子串。比如下面这个例子,
Pattern p=Pattern.compile("reg");
Matcher m=p.matcher("regular");
System.out.println(m.lookingAt());
//output: true
单词regular的开头包含reg子串,所以匹配成功。
组
之前讲过,正则表达式用括号括起来的部分都是一个“组”。每个组在正则表达式里,都有自己的序号。序号是这样定义的: 假设有 “A(B(C))D” 这个正则表达式,一共有三个组:
- Group 0:就是全体”ABCD”
- Group 1:就是左起第一个括号里的内容”BC”
- Group 2:是左起第二个括号里的”C”
如果上面的find(),matches(),lookingAt()方法,匹配成功的话,调用Matcher#group()无参数方法,可以返回序号是0的组,也就是全体。Matcher#group(int i)方法就返回对应序号的组。
appendReplacement(StringBuffer sbuf, String replacement)和appendTail(StringBuffer sbuf)
正常情况下,如果每次替换的内容都一样,appendReplacement()其实和replaceAll()的效果一样。但appendReplacement()的优势是渐进式替换,
while(m.find()){
m.appendReplacement(sbuf, m.group().toUpperCase());
}
m.appendTail(sbuf);
上面的代码每次用的都是大写替换小写m.group().toUpperCase()。但因为可以调用一个函数来生成替换内容,这部分我们可以在里面做很大的文章,设计成每次特换不同的内容。
Matcher#reset( )
reset()方法可以将现有Matcher应用于一个新的字符串。这样就可以重复使用构造好的某个pattern。效率更高。例子如下,
Pattern p=Pattern.compile("reg");
Matcher m=p.matcher("regular");
System.out.println(m.lookingAt());
//不换表达式"reg",直接换一段目标字符串来匹配。
m.reset("expression");
System.out.println(m.lookingAt());
//output:
//true
//false
上面代码中的m.reset(“expression”)在不换正则表达式”reg”的情况下,直接换一段目标字符串来匹配。
总结
正则表达式很重要,需要以后在工作中熟练操作。
String很底层,和虚拟机结合地很深。里面有很多学问。越是常见基本的东西,越是容易被人忽视。但其中往往有大乾坤。
练习
Exercise 1
- Exercise 1: (2) Analyze SprinklerSystem.toString( ) in reusing/SprinklerSystem.java to discover whether writing the toString( ) with an explicit StringBuilder will save any StringBuilder creations.
第二种toStringBuilder()方法没有减少StringBuilder的数量。原因是第一个toString()方法已经优化过,也只产生了一个StringBuilder对象。因为没有在循环里拼接String,所以没有产生很多中间StringBuilder。
Exercise1.java
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
public class Exercise1{
private final String valve1="Monday";
private final String valve2="Tusday";
private final String valve3="Wendsday";
private final String valve4="Thursday";
private WaterSource source = new WaterSource();
private int i;
private float f;
//use String
//每进行一次“+”操作,就产生一个StringBuilder对象。
public String toString() {
long begin=System.nanoTime();
String result=
"valve1 = " + valve1 + " " +
"valve2 = " + valve2 + " " +
"valve3 = " + valve3 + " " +
"valve4 = " + valve4 + "\n" +
"i = " + i + " " + "f = " + f + " " +
"source = " + source;
long end=System.nanoTime();
System.out.println((end-begin)/10e6);
return result;
}
//use StringBuilder
//只产生一个StringBuilder对象
public String toStringBuilder() {
long begin=System.nanoTime();
StringBuilder result=new StringBuilder();
result.append("valve1 = ").append(valve1).append(" ");
result.append("valve2 = ").append(valve2).append(" ");
result.append("valve3 = ").append(valve3).append(" ");
result.append("valve4 = ").append(valve4).append("\n");
result.append("i = ").append(i).append(" ").append("f = ").append(f).append(" ").append("source = ").append(source);
long end=System.nanoTime();
System.out.println((end-begin)/10e6);
return result.toString();
}
public static void main(String[] args) {
Exercise1 sprinklers = new Exercise1();
System.out.println(sprinklers);
System.out.println(sprinklers.toStringBuilder());
}
}
WaterSource.Java
package com.ciaoshen.thinkinjava.chapter13;
public class WaterSource {
private String s;
public WaterSource() {
System.out.println("WaterSource()");
s = "Constructed";
}
public String toString() { return s; }
}
Exercise 2
- Exercise 2: (1) Repair InfiniteRecursion.java.
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
public class Exercise2{
public String toString() {
return " InfiniteRecursion address: " + super.toString() + "\n";
}
public static void main(String[] args) {
List<Exercise2> v = new ArrayList<Exercise2>();
for(int i = 0; i < 10; i++){
v.add(new Exercise2());
}
System.out.println(v);
}
}
Exercise 3
- Exercise 3: (1) Modify Turtle.java so that it sends all output to System.err.
package com.ciaoshen.thinkinjava.chapter13;
import java.io.*;
import java.util.*;
public class Exercise3{
private String name;
private Formatter f;
public Exercise3(String name, Formatter f) {
this.name = name;
this.f = f;
}
public void move(int x, int y) {
f.format("%s The Turtle is at (%d,%d)\n", name, x, y);
}
public static void main(String[] args) {
PrintStream errAlias= System.err;
Exercise3 tommy = new Exercise3("Tommy",new Formatter(System.err));
Exercise3 terry = new Exercise3("Terry",new Formatter(errAlias));
tommy.move(0,0);
terry.move(4,8);
tommy.move(3,4);
terry.move(2,5);
tommy.move(3,3);
terry.move(3,3);
}
}
Exercise 4
- Exercise 4: (3) Modify Receipt.java so that the widths are all controlled by a single set of constant values. The goal is to allow you to easily change a width by changing a single value in one place.
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
public class Exercise4 {
private double total = 0;
private Formatter f = new Formatter(System.out);
private int[] columnsWidth={15,5,10};
public Exercise4(){}
public Exercise4(int[] width){columnsWidth=width;}
public void printTitle() {
f.format("%-"+columnsWidth[0]+"s %"+columnsWidth[1]+"s %"+columnsWidth[2]+"s\n", "Item", "Qty", "Price");
f.format("%-"+columnsWidth[0]+"s %"+columnsWidth[1]+"s %"+columnsWidth[2]+"s\n", "----", "---", "-----");
}
public void print(String name, int qty, double price) {
f.format("%-"+columnsWidth[0]+".15s %"+columnsWidth[1]+"d %"+columnsWidth[2]+".2f\n", name, qty, price);
total += price;
}
public void printTotal() {
f.format("%-"+columnsWidth[0]+"s %"+columnsWidth[1]+"s %"+columnsWidth[2]+".2f\n", "Tax", "", total*0.06);
f.format("%-"+columnsWidth[0]+"s %"+columnsWidth[1]+"s %"+columnsWidth[2]+"s\n", "", "", "-----");
f.format("%-"+columnsWidth[0]+"s %"+columnsWidth[1]+"s %"+columnsWidth[2]+".2f\n", "Total", "", total * 1.06);
}
public static void main(String[] args) {
int[] width={30,10,20};
Exercise4 receipt = new Exercise4(width);
receipt.printTitle();
receipt.print("Jack’s Magic Beans", 4, 4.25);
receipt.print("Princess Peas", 3, 5.1);
receipt.print("Three Bears Porridge", 1, 14.29);
receipt.printTotal();
}
}
Exercise 5
- Exercise 5: (5) For each of the basic conversion types in the above table, write the most complex formatting expression possible. That is, use all the possible format specifiers available for that conversion type.
package com.ciaoshen.thinkinjava.chapter13;
import java.math.*;
import java.util.*;
public class Exercise5{
public static void main(String[] args) {
Formatter f = new Formatter(System.out);
char u = 'a';
System.out.println("u = ‘a’");
f.format("s: %1$-15.15s\n", u);
// f.format("d: %d\n", u);
f.format("c: %1$-15c\n", u);
f.format("b: %1$-15.5b\n", u);
// f.format("f: %f\n", u);
// f.format("e: %e\n", u);
// f.format("x: %x\n", u);
f.format("h: %1$-15.5h\n", u);
}
}
Exercise 6
- Exercise 6: (2) Create a class that contains int, long, float and double fields. Create a toString( ) method for this class that uses String.format( ), and demonstrate that your class works correctly.
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
public class Exercise6 {
private static final int i=100;
private static final long l=10000l;
private static final float f=10000.00f;
private static final double d=100000.00;
public String toString(){
return String.format("Int: %1$-15d Long: %2$-15d Float: %3$-15.1f Double: %4$-15.7e", i, l, f, d);
}
public static void main(String[] args){
Exercise6 ex=new Exercise6();
System.out.println(ex);
}
}
Exercise 7
- Exercise 7: (5) Using the documentation for java.util.regex.Pattern as a resource, write and test a regular expression that checks a sentence to see that it begins with a capital letter and ends with a period.
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
import java.util.regex.*;
public class Exercise7 {
private List<String> list=new ArrayList<String>();
public Exercise7(){}
public Exercise7(List<String> l){list=l;}
public void setList(List<String> l){list=l;}
public void parse(String regex){
Pattern p=Pattern.compile(regex);
Matcher m;
Formatter f=new Formatter(System.out);
for(String str:list){
m=p.matcher(str);
f.format("%1$-15.15s %2$-8.8s\n", str, m.find());
}
}
public static void main(String[] args){
Exercise7 test=new Exercise7(Arrays.asList("hello world!","Hello world!","Hello World!","Hello world.","Hello World.","HELLO WORLD."));
String regex="^[A-Z].*\\.";
test.parse(regex);
}
}
Exercise 8
- Exercise 8: (2) Split the string Splitting.knights on the words “the” or “you.”
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
public class Exercise8 {
private static final String knight =
"Then, when you have found the shrubbery, you must cut " +
"down the mightiest tree in the forest... " +
"with... a herring!";
public static void split(String regex) {
Formatter f = new Formatter(System.out);
List<String> list = Arrays.asList(knight.split(regex));
for(String str : list){
f.format("%50.50s\n", str);
}
}
public static void main(String[] args){
Exercise8.split("the | you");
}
}
Exercis 9
- Exercise 9: (4) Using the documentation for java.util.regex.Pattern as a resource, replace all the vowels in Splitting.knights with underscores.
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
public class Exercise9{
private static final String knight =
"Then, when you have found the shrubbery, you must cut " +
"down the mightiest tree in the forest... " +
"with... a herring!";
public static void replace(String regex, String replacement){
System.out.println(knight.replaceAll(regex,replacement));
}
public static void main(String[] args){
Exercise9.replace("[aeiouAEIOU]","_");
}
}
Exercise 10
- Exercise 10: (2) For the phrase “Java now has regular expressions” evaluate whether the following expressions will find a match:
^Java,\Breg.*,n.w\s+h(a|i)s,s?,s*,s+,s{4},S{1}.,s{0,3}.
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
import java.util.regex.*;
public class Exercise11 {
private static final String phrase = "Arline ate eight apples and one orange while Anita hadn't any";
public static boolean finding(String regex){
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(phrase);
return m.find();
}
public static void main(String[] args){
String regex = "(?i)((^[aeiou])|(\\s+[aeiou]))\\w+?[aeiou]\\b";
System.out.println(Exercise11.finding(regex));
}
}
Exercise 12
- Exercise 12: (5) Modify Groups.java to count all of the unique words that do not start with a capital letter.
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
import java.util.regex.*;
public class Exercise12 {
protected static final String POEM =
"Twas brillig, and the slithy toves\n" +
"Did gyre and gimble in the wabe.\n" +
"All mimsy were the borogoves,\n" +
"And the mome raths outgrabe.\n\n" +
"Beware the Jabberwock, my son,\n" +
"The jaws that bite, the claws that catch.\n" +
"Beware the Jubjub bird, and shun\n" +
"The frumious Bandersnatch.";
public static Set<String> scan(String regex){
Set<String> set = new HashSet<String>();
Matcher m = Pattern.compile(regex).matcher(POEM);
while(m.find()){
set.add(m.group(2));
}
return set;
}
public static void display(Set<String> set){
System.out.println("Word count: " + set.size());
System.out.println(set);
}
public static void main(String[] args) {
String regex = "(?m)(^|\\W)([a-z]\\w*)(\\W|$)";
Exercise12.display(Exercise12.scan(regex));
}
}
Exercise 13
- Exercise 13: (2) Modify StartEnd.java so that it uses Groups.POEM as input, but still produces positive outputs for find( ), lookingAt( ) and matches( ).
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
import java.util.regex.*;
public class Exercise13 {
public static String input = Exercise12.POEM;
private static class Display {
private boolean regexPrinted = false;
private String regex;
Display(String regex) { this.regex = regex; }
void display(String message) {
if(!regexPrinted) {
System.out.println(regex);
regexPrinted = true;
}
System.out.println(message);
}
}
static void examine(String s, String regex) {
Display d = new Display(regex);
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(s);
while(m.find()){
d.display("find() ‘" + m.group() + "‘ start = "+ m.start() + " end = " + m.end());
}
if(m.lookingAt()){ // No reset() necessary
d.display("lookingAt() start = " + m.start() + " end = " + m.end());
}
if(m.matches()){ // No reset() necessary
d.display("matches() start = " + m.start() + " end = " + m.end());
}
}
public static void main(String[] args) {
for(String in : input.split("\n")) {
System.out.println("input : " + in);
for(String regex : new String[]{"\\w*ere\\w*","\\w*are", "T\\w+", "Twas.*?"}){
examine(in, regex);
}
}
}
}
Exercise 14
- Exercise 14: (1) Rewrite SplitDemo using String.split( ).
package com.ciaoshen.thinkinjava.chapter13;
import java.util.regex.*;
import java.util.*;
public class Exercise14 {
private static final String phrase = "This!!unusual use!!of exclamation!!points";
public static void split(String regex){
System.out.println(Arrays.toString(phrase.split(regex)));
}
public static void splitThreePieces(String regex){
System.out.println(Arrays.toString(phrase.split(regex,3)));
}
public static void main(String[] args) {
String regex = "!!";
Exercise14.split(regex);
Exercise14.splitThreePieces(regex);
}
}
Exercise 15
- Exercise 15: (5) Modify JGrep.java to accept flags as arguments (e.g., Pattern.CASE_INSENSITIVE, Pattern.MULTILINE).
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
import java.util.regex.*;
import java.io.*;
public class Exercise15 {
private static final String SPLITER = "\n";
private static String readFile(String path){ //return the file content as a string, otherwise return null
StringBuilder sb = new StringBuilder();
File f = new File(path);
try{
BufferedReader br = new BufferedReader(new FileReader(new File(path)));
try{
String line = null;
while(true){
line = br.readLine();
if(line == null){break;}
sb.append(line+SPLITER);
}
return sb.toString();
}finally{
br.close();
}
}catch(IOException ioe){
System.out.println("IOException when openning file " + path);
return null;
}
}
public static void grep(String regex, String path, int flag){
String content = readFile(path);
if(content == null){System.out.println("Check your file path: " + path);return;}
Pattern p = Pattern.compile(regex, flag);
Matcher m = p.matcher("");
Formatter f = new Formatter(System.out);
int index=0;
f.format("%1$5.5s %2$-15.15s %3$5.5s \n", "INDEX", "WORD", "POS");
for(String line : content.split(SPLITER)){
m.reset(line);
while(m.find()){
f.format("%1$5d: %2$-15.15s %3$5d \n",++index, m.group(), m.start());
}
}
}
private static void unitTestReadFile(){ //test readFile()
String rightPath = "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/Exercise15.java";
String wrongPath = "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/Exercise.java";
System.out.println(readFile(rightPath));
System.out.println(readFile(wrongPath));
}
private static void unitTestGrep(String regex){ //test grep()
String rightPath = "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/Exercise15.java";
String wrongPath = "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/Exercise.java";
int flag = Pattern.CASE_INSENSITIVE;
grep(regex, rightPath, flag);
grep(regex, wrongPath, flag);
}
public static void main(String[] args){
//单元测试
//Exercise15.unitTestReadFile();
//Exercise15.unitTestGrep("s\\w*");
Exercise15.unitTestGrep("(?)(^|\\W)(s\\w*)(\\W|$)");
}
}
Exercise 16
- Exercise 16: (5) Modify JGrep.java to accept a directory name or a file name as argument (if a directory is provided, search should include all files in the directory). Hint: You can generate a list of file names with:
File[] files = new File(".").listFiles();
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
import java.util.regex.*;
import java.io.*;
public class Exercise16 {
private static final String SPLITER = "\n";
private static String readFile(String path){ //return the file content as a string, otherwise return null
StringBuilder sb = new StringBuilder();
File f = new File(path);
try{
BufferedReader br = new BufferedReader(new FileReader(new File(path)));
try{
String line = null;
while(true){
line = br.readLine();
if(line == null){break;}
sb.append(line+SPLITER);
}
return sb.toString();
}finally{
br.close();
}
}catch(IOException ioe){
System.out.println("IOException when openning file " + path);
return null;
}
}
private static List<File> extracDir(String path){
File f = new File(path);
if(!f.exists()){System.out.println(path + " doesn't exist!");}
if(f.isFile()){return Arrays.asList(f);}
if(f.isDirectory()){
List<File> list = new ArrayList<File>();
File[] files = f.listFiles();
for(File file : files){
list.addAll(extracDir(file.getAbsolutePath()));
}
return list;
}
return new ArrayList<File>();
}
public static void grep(String regex, String path, int flag){
int index=0;
List<File> list = extracDir(path);
for(File file : list){
System.out.println("\n" + ">>> " + file.getAbsolutePath());
String content = readFile(file.getAbsolutePath());
if(content == null){System.out.println("Check your file path: " + path);return;}
Pattern p = Pattern.compile(regex, flag);
Matcher m = p.matcher("");
Formatter f = new Formatter(System.out);
f.format("%1$5.5s %2$-15.15s %3$5.5s \n", "INDEX", "WORD", "POS");
for(String line : content.split(SPLITER)){
m.reset(line);
while(m.find()){
f.format("%1$5d: %2$-15.15s %3$5d \n",++index, m.group(2), m.start());
}
}
}
}
private static void unitTestExtracDir(){
String wrongPath = "/Users/Wei/java/helloKitty.java";
String filePath = "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/Exercise16.java";
String dirPath= "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13";
System.out.println(extracDir(dirPath));
System.out.println("=================================");
System.out.println(extracDir(filePath));
System.out.println("=================================");
System.out.println(extracDir(wrongPath));
}
private static void unitTestReadFile(){ //test readFile()
String rightPath = "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/Exercise15.java";
String wrongPath = "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/Exercise.java";
System.out.println(readFile(rightPath));
System.out.println(readFile(wrongPath));
}
private static void unitTestGrep(String regex){ //test grep()
String dirPath = "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13";
String filePath = "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/Exercise15.java";
String wrongPath = "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/Exercise.java";
int flag = Pattern.CASE_INSENSITIVE;
grep(regex, dirPath, flag);
System.out.println("=================================");
grep(regex, filePath, flag);
System.out.println("=================================");
grep(regex, wrongPath, flag);
}
public static void main(String[] args){
//单元测试
//Exercise16.unitTestReadFile();
//Exercise16.unitTestExtracDir();
//Exercise16.unitTestGrep("s\\w*");
Exercise16.unitTestGrep("(?)(^|\\W)(s\\w*)(\\W|$)");
}
}
Exercise 17
- Exercise 17: (8) Write a program that reads a Java source-code file (you provide the file name on the command line) and displays all the comments.
不可能写出十全十美的能找出所有注释的正则表达式。我只能尽我所能,有条理地匹配几种最常见的情况。仅适用于遵守Google推荐编程风格的代码。
- //简单注释
- / * 单行正式注释 * /
- / * 多行注释 * /
- 如果注释在双引号”“里,就不是注释
- 前面有转义符反斜杠的不是双引号
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
import java.util.regex.*;
import java.io.*;
public class Exercise17 {
private static final String SPLITER = "\n";
private static boolean isInFormalAnnotation = false;
// open a file, return a string, return null otherwise
public static String readFile(String path) {
File inFile = new File(path);
if( !inFile.exists() || !inFile.isFile() ) {
System.out.println("Path ERROR! Check your path " + path);
return null;
}
StringBuilder resultString = new StringBuilder();
try {
BufferedReader buffReader = new BufferedReader( new FileReader( inFile) );
try {
String textLine = new String("");
while (true) {
textLine = buffReader.readLine();
if (textLine == null) {
break;
}
resultString.append(textLine + SPLITER);
}
} finally {
buffReader.close();
}
} catch (IOException ioe) {
System.out.println( "ERROR when reading the file " + inFile.getName() );
}
return resultString.toString();
}
// print all annotation
public static void scanAnnotation(String path){
String content = readFile(path);
if (content == null || content.isEmpty()) {
System.out.println("Method scan() cannot read file " + path);
return;
}
String simpleAnnotation = new String("");
String formalAnnotation = new String("");
for (String line : content.split(SPLITER)) {
//main procedure
simpleAnnotation = getSimpleAnnotation(line);
if(simpleAnnotation != null) {
System.out.println(simpleAnnotation);
}
formalAnnotation = getFormalAnnotation(line);
if(formalAnnotation != null) {
System.out.println(formalAnnotation);
}
}
}
// box-1.
// input: string line,
// output: return simple annotation. otherwise return null
private static String getSimpleAnnotation(String line) {
String simpleAnnotationRegex = "\\s//";
Matcher simpleAnnotationMatcher = Pattern.compile(simpleAnnotationRegex).matcher(line);
while (simpleAnnotationMatcher.find()) {
if (!isInStringQuote(line.substring(0, simpleAnnotationMatcher.start()))) {
return line.substring(simpleAnnotationMatcher.start());
}
}
return null;
}
// box-2.
// input: string line,
// output: return formal annotation. otherwise return null
private static String getFormalAnnotation(String line) {
String formalBeginRegex = "/\\*";
String formalEndRegex = "\\*/";
if (!isInFormalAnnotation) {
Matcher formalBeginMatcher = Pattern.compile(formalBeginRegex).matcher(line);
while (formalBeginMatcher.find()) {
if (!isInStringQuote(line.substring(0,formalBeginMatcher.start()))) {
isInFormalAnnotation = true;
String subLine = line.substring(formalBeginMatcher.start());
Matcher formalEndMatcher = Pattern.compile(formalEndRegex).matcher(subLine);
if (formalEndMatcher.find()) {
isInFormalAnnotation = false;
return subLine.substring(0,formalEndMatcher.end());
}
return subLine;
}
}
} else {
Matcher formalEndMatcher = Pattern.compile(formalEndRegex).matcher(line);
if (formalEndMatcher.find()) {
isInFormalAnnotation = false;
}
return line;
}
return null;
}
/*
* box-3
* input: prefix of annotation line
* output: boolean. if this prefix text is in string quote.
*/
private static boolean isInStringQuote(String prefix) {
String doubleQuoteRegex = "[^\\\\]\".*?[^\\\\]\"|\"\"";
Matcher doubleQuoteMatcher = Pattern.compile(doubleQuoteRegex).matcher(prefix);
if(! doubleQuoteMatcher.find()) {
String singleQuoteRegex = "[^\\\\]\"";
Matcher singleQuoteMatcher = Pattern.compile(singleQuoteRegex).matcher(prefix);
return singleQuoteMatcher.find();
} else {
return isInStringQuote(prefix.replaceFirst(doubleQuoteRegex, ""));
}
}
private static void testUnitScanAnnotation() {
String wrongPath = "/Users/helloKitty/java/com/ciaoshen/thinkinjava/chapter13/Exercise17.java";
String rightPath= "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/Exercise17.java";
Exercise17.scanAnnotation(rightPath);
Exercise17.scanAnnotation(wrongPath);
}
private static void testIsInStringQuote(String prefix) {
System.out.println(isInStringQuote(prefix));
}
public static void main(String[] args) {
String testPatternString = "a" + "b //假注释" + "c" + "d"; /*给注释匹配模式出个难题*/
String testPatternString2 = "\"a\" + \"b //假注释";
Exercise17.testUnitScanAnnotation();
//Exercise17.testIsInStringQuote(testPatternString);
//Exercise17.testIsInStringQuote(testPatternString2);
}
}
Exercise 18
- Exercise 18: (8) Write a program that reads a Java source-code file (you provide the file name on the command line) and displays all the string literals in the code.
利用了第17题的部分代码。因为如果引号里的字符串在注释里,就不算字符串。所以本题,先利用17题把注释全部过滤掉,再开始匹配字符串。所以代码被设计成两层独立的过滤器,一个过滤注释,一个过滤字符串。后面的19题也会用到17,18题的两个过滤器把可能的干扰项排除干净。
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
import java.util.regex.*;
import java.io.*;
public class Exercise18 {
private static final String SPLITER = "\n";
private static boolean isInFormalAnnotation = false;
// open a file, return a string, return null otherwise
public static String readFile(String path) {
File inFile = new File(path);
if( !inFile.exists() || !inFile.isFile() ) {
System.out.println("Path ERROR! Check your path " + path);
return null;
}
StringBuilder resultString = new StringBuilder();
try {
BufferedReader buffReader = new BufferedReader( new FileReader( inFile) );
try {
String textLine = new String("");
while (true) {
textLine = buffReader.readLine();
if (textLine == null) {
break;
}
resultString.append(textLine + SPLITER);
}
} finally {
buffReader.close();
}
} catch (IOException ioe) {
System.out.println( "ERROR when reading the file " + inFile.getName() );
}
return resultString.toString();
}
// erase all annotation
public static String eraseAnnotation(String path){
StringBuilder resultBuilder = new StringBuilder();
String content = readFile(path);
if (content == null || content.isEmpty()) {
System.out.println("Method scan() cannot read file " + path);
return null;
}
String noSimpleAnnotation = new String("");
String noFormalAnnotation = new String("");
for (String line : content.split(SPLITER)) {
//main procedure
noSimpleAnnotation = eraseSimpleAnnotation(line);
noFormalAnnotation= eraseFormalAnnotation(noSimpleAnnotation);
if (noFormalAnnotation != null) {
System.out.println(noFormalAnnotation);
resultBuilder.append(noFormalAnnotation + SPLITER);
}
}
return resultBuilder.toString();
}
// box-1.
// input: string line,
// output: erase simple annotation.
private static String eraseSimpleAnnotation(String line) {
String simpleAnnotationRegex = "\\s//";
Matcher simpleAnnotationMatcher = Pattern.compile(simpleAnnotationRegex).matcher(line);
while (simpleAnnotationMatcher.find()) {
if (!isInStringQuote(line.substring(0, simpleAnnotationMatcher.start()))) {
return line.substring(0, simpleAnnotationMatcher.start());
}
}
return line;
}
// box-2.
// input: string line,
// output: erase the formal annotation.
private static String eraseFormalAnnotation(String line) {
String formalBeginRegex = "/\\*";
String formalEndRegex = "\\*/";
if (!isInFormalAnnotation) {
Matcher formalBeginMatcher = Pattern.compile(formalBeginRegex).matcher(line);
while (formalBeginMatcher.find()) {
if (!isInStringQuote(line.substring(0,formalBeginMatcher.start()))) {
isInFormalAnnotation = true;
String subLine = line.substring(formalBeginMatcher.start());
Matcher formalEndMatcher = Pattern.compile(formalEndRegex).matcher(subLine);
if (formalEndMatcher.find()) {
isInFormalAnnotation = false;
return line.replace(subLine.substring(0,formalEndMatcher.end()),"");
}
return line.replace(subLine,"");
}
}
} else {
Matcher formalEndMatcher = Pattern.compile(formalEndRegex).matcher(line);
if (formalEndMatcher.find()) {
isInFormalAnnotation = false;
}
return null;
}
return line;
}
/*
* box-3
* input: prefix of annotation line
* output: boolean. if this prefix text is in string quote.
*/
private static boolean isInStringQuote(String prefix) {
String doubleQuoteRegex = "[^\\\\]\".*?[^\\\\]\"";
Matcher doubleQuoteMatcher = Pattern.compile(doubleQuoteRegex).matcher(prefix);
if(! doubleQuoteMatcher.find()) {
String singleQuoteRegex = "[^\\\\]\"";
Matcher singleQuoteMatcher = Pattern.compile(singleQuoteRegex).matcher(prefix);
return singleQuoteMatcher.find();
} else {
return isInStringQuote(prefix.replaceFirst(doubleQuoteRegex, ""));
}
}
// box-4
// input: entire text file
// output: erase all literal string in double quote
private static String filterLiteralString(String content) {
StringBuilder resultBuilder = new StringBuilder();
for (String line : content.split(SPLITER)) {
resultBuilder.append(eraseLiteralString(line) + SPLITER);
}
return resultBuilder.toString();
}
// box-5
// input: line string
// output: erase literal string in double quote
private static String eraseLiteralString(String line) {
String doubleQuoteRegex = "[^\\\\]\".*?[^\\\\]\"|\"\"";
return line.replaceAll(doubleQuoteRegex,"");
}
private static void start(String path) {
String noAnnotation = eraseAnnotation(path);
String noLiteral = filterLiteralString(noAnnotation);
System.out.println(noLiteral);
}
private static void testUnitEraseAnnotation() {
String wrongPath = "/Users/helloKitty/java/com/ciaoshen/thinkinjava/chapter13/Exercise18.java";
String rightPath = "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/Exercise18.java";
Exercise18.eraseAnnotation(rightPath);
Exercise18.eraseAnnotation(wrongPath);
}
private static void testIsInStringQuote(String prefix) {
System.out.println(isInStringQuote(prefix));
}
private static void testUnitEraseLiteralString(String phrase) {
System.out.println(eraseLiteralString(phrase));
}
private static void testUnitFilterLiteralString(String content) {
System.out.println(filterLiteralString(content));
}
private static void testUnitStart() {
String wrongPath = "/Users/helloKitty/java/com/ciaoshen/thinkinjava/chapter13/Exercise18.java";
String rightPath= "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/Exercise18.java";
Exercise18.start(rightPath);
Exercise18.start(wrongPath);
}
public static void main(String[] args) {
String testPatternString = "a" + "b //假注释" + "c" + "d"; /*给注释匹配模式出个难题*/
String testPatternString2 = "\"a\" + \"b //假注释";
//Exercise18.testUnitEraseAnnotation();
//Exercise18.testIsInStringQuote(testPatternString);
//Exercise18.testIsInStringQuote(testPatternString2);
//Exercise18.testUnitEraseLiteralString(testPatternString);
//Exercise18.testUnitEraseLiteralString(testPatternString2);
Exercise18.testUnitStart();
}
}
Exercise 19
- Exercise 19: (8) Building on the previous two exercises, write a program that examines Java source code and produces all the class names used in a particular program.
基于17,18两题的成果,先把干扰项comments和literal清除干净。剩下的根据Google Java推荐编程风格,大驼峰ClassName的都是类名,只要找大写字母开头的单词就可以了。
package com.ciaoshen.thinkinjava.chapter13;
import java.util.*;
import java.util.regex.*;
import java.io.*;
public class Exercise19 {
private static final String SPLITER = "\n";
private static boolean isInFormalAnnotation = false;
// open a file, return a string, return null otherwise
public static String readFile(String path) {
File inFile = new File(path);
if( !inFile.exists() || !inFile.isFile() ) {
System.out.println("Path ERROR! Check your path " + path);
return null;
}
StringBuilder resultString = new StringBuilder();
try {
BufferedReader buffReader = new BufferedReader( new FileReader( inFile) );
try {
String textLine = new String("");
while (true) {
textLine = buffReader.readLine();
if (textLine == null) {
break;
}
resultString.append(textLine + SPLITER);
}
} finally {
buffReader.close();
}
} catch (IOException ioe) {
System.out.println( "ERROR when reading the file " + inFile.getName() );
}
return resultString.toString();
}
// erase all annotation
public static String filterAnnotation(String path){
StringBuilder resultBuilder = new StringBuilder();
String content = readFile(path);
if (content == null || content.isEmpty()) {
System.out.println("Method scan() cannot read file " + path);
return null;
}
String noSimpleAnnotation = new String("");
String noFormalAnnotation = new String("");
for (String line : content.split(SPLITER)) {
//main procedure
noSimpleAnnotation = eraseSimpleAnnotation(line);
noFormalAnnotation= eraseFormalAnnotation(noSimpleAnnotation);
if (noFormalAnnotation != null) {
//System.out.println(noFormalAnnotation);
resultBuilder.append(noFormalAnnotation + SPLITER);
}
}
return resultBuilder.toString();
}
// box-1.
// input: string line,
// output: erase simple annotation.
private static String eraseSimpleAnnotation(String line) {
String simpleAnnotationRegex = "\\s//";
Matcher simpleAnnotationMatcher = Pattern.compile(simpleAnnotationRegex).matcher(line);
while (simpleAnnotationMatcher.find()) {
if (!isInStringQuote(line.substring(0, simpleAnnotationMatcher.start()))) {
return line.substring(0, simpleAnnotationMatcher.start());
}
}
return line;
}
// box-2.
// input: string line,
// output: erase the formal annotation.
private static String eraseFormalAnnotation(String line) {
String formalBeginRegex = "/\\*";
String formalEndRegex = "\\*/";
if (!isInFormalAnnotation) {
Matcher formalBeginMatcher = Pattern.compile(formalBeginRegex).matcher(line);
while (formalBeginMatcher.find()) {
if (!isInStringQuote(line.substring(0,formalBeginMatcher.start()))) {
isInFormalAnnotation = true;
String subLine = line.substring(formalBeginMatcher.start());
Matcher formalEndMatcher = Pattern.compile(formalEndRegex).matcher(subLine);
if (formalEndMatcher.find()) {
isInFormalAnnotation = false;
return line.replace(subLine.substring(0,formalEndMatcher.end()),"");
}
return line.replace(subLine,"");
}
}
} else {
Matcher formalEndMatcher = Pattern.compile(formalEndRegex).matcher(line);
if (formalEndMatcher.find()) {
isInFormalAnnotation = false;
}
return null;
}
return line;
}
/*
* box-3
* input: prefix of annotation line
* output: boolean. if this prefix text is in string quote.
*/
private static boolean isInStringQuote(String prefix) {
String doubleQuoteRegex = "(^|\\s*)\".*?[^\\\\]\"|\"\"";
Matcher doubleQuoteMatcher = Pattern.compile(doubleQuoteRegex).matcher(prefix);
if(! doubleQuoteMatcher.find()) {
String singleQuoteRegex = "[^\\\\]\"";
Matcher singleQuoteMatcher = Pattern.compile(singleQuoteRegex).matcher(prefix);
return singleQuoteMatcher.find();
} else {
return isInStringQuote(prefix.replaceFirst(doubleQuoteRegex, ""));
}
}
// box-4
// input: entire text file
// output: erase all literal string in double quote
private static String filterLiteralString(String content) {
if (content == null || content.isEmpty()) {
System.out.println("filterLiteralString() get null content!");
return null;
}
StringBuilder resultBuilder = new StringBuilder();
for (String line : content.split(SPLITER)) {
resultBuilder.append(eraseLiteralString(line) + SPLITER);
}
return resultBuilder.toString();
}
// box-5
// input: line string
// output: erase literal string in double quote
private static String eraseLiteralString(String line) {
String doubleQuoteRegex = "(^|\\s*)\".*?[^\\\\]\"|\"\"";
Matcher doubleQuoteMatcher = Pattern.compile(doubleQuoteRegex).matcher(line);
while (doubleQuoteMatcher.find()) {
line = line.replace(doubleQuoteMatcher.group(),"");
}
return line;
}
private static String filterEmptyLine(String content) { //删除空行
if (content == null || content.isEmpty()) {
System.out.println("filterEmptyLine() get null content!");
return null;
}
String emptyRegex = "(?m)^\\s*$";
StringBuilder resultBuilder = new StringBuilder();
Matcher emptyMatcher = Pattern.compile(emptyRegex).matcher("");
for (String line : content.split(SPLITER)) {
emptyMatcher = emptyMatcher.reset(line);
if (!emptyMatcher.find()) {
resultBuilder.append(line + SPLITER);
}
}
return resultBuilder.toString();
}
private static Set<String> segmentWords(String content) {
if (content == null || content.isEmpty()) {
System.out.println("segmentWords() get null content!");
return null;
}
Set<String> wordsFound = new HashSet<String>();
String wordsRegex = "\\W([A-Z]\\w*)";
Matcher wordsMatcher = Pattern.compile(wordsRegex).matcher("");
for (String line : content.split(SPLITER)) {
wordsMatcher = wordsMatcher.reset(line);
while (wordsMatcher.find()) {
wordsFound.add(wordsMatcher.group(1));
}
}
return wordsFound;
}
private static void start(String path) {
String noAnnotation = filterAnnotation(path);
String noLiteral = filterLiteralString(noAnnotation);
String meaningfulCode = filterEmptyLine(noLiteral);
Set<String> className = segmentWords(meaningfulCode);
System.out.println(className);
}
private static void testUnitFilterAnnotation() {
String wrongPath = "/Users/helloKitty/java/com/ciaoshen/thinkinjava/chapter13/Exercise19.java";
String rightPath = "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/Exercise19.java";
Exercise19.filterAnnotation(rightPath);
Exercise19.filterAnnotation(wrongPath);
}
private static void testIsInStringQuote(String prefix) {
System.out.println(isInStringQuote(prefix));
}
private static void testUnitEraseLiteralString(String phrase) {
System.out.println(eraseLiteralString(phrase));
}
private static void testUnitFilterLiteralString(String content) {
System.out.println(filterLiteralString(content));
}
private static void testUnitStart() {
String wrongPath = "/Users/helloKitty/java/com/ciaoshen/thinkinjava/chapter13/Exercise19.java";
String rightPath= "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/Exercise19.java";
Exercise19.start(rightPath);
Exercise19.start(wrongPath);
}
private static void testUnitDoubleQuotePattern(String regex) {
String path = "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/quote.txt";
Matcher doubleQuoteMatcher = Pattern.compile(regex).matcher("");
String content = readFile(path);
for(String line : content.split(SPLITER)) {
doubleQuoteMatcher = doubleQuoteMatcher.reset(line);
System.out.println("FOUND");
while (doubleQuoteMatcher.find()) {
System.out.println(" >>>" + doubleQuoteMatcher.group());
}
}
}
private static void testUnitDoubleQuoteReplace(String regex) {
String path = "/Users/Wei/java/com/ciaoshen/thinkinjava/chapter13/quote.txt";
Matcher doubleQuoteMatcher = Pattern.compile(regex).matcher("");
String content = readFile(path);
for(String line : content.split(SPLITER)) {
doubleQuoteMatcher = doubleQuoteMatcher.reset(line);
System.out.println("FOUND");
while (doubleQuoteMatcher.find()) {
System.out.println(" >>>" + doubleQuoteMatcher.group());
line = line.replace(doubleQuoteMatcher.group(),"");
}
System.out.println(line);
}
}
public static void main(String[] args) {
String testPatternString = "a" + "b //假注释" + "c" + "d"; /*给注释匹配模式出个难题*/
String testPatternString2 = "\"a\" + \"b //假注释";
//Exercise19.testUnitFilterAnnotation();
//Exercise19.testIsInStringQuote(testPatternString);
//Exercise19.testIsInStringQuote(testPatternString2);
//Exercise19.testUnitEraseLiteralString(testPatternString);
//Exercise19.testUnitEraseLiteralString(testPatternString2);
Exercise19.testUnitStart();
String doubleQuoteRegex1 = "\".*\"";
String doubleQuoteRegex2 = "\".*?\"";
String doubleQuoteRegex3 = "[^\\\\]\".*?[^\\\\]\"";
String doubleQuoteRegex4 = "[^\\\\]\".*?[^\\\\]\"|^\".*?[^\\\\]\"|\"\"";
String doubleQuoteRegex5 = "(^|\\s*)\".*?[^\\\\]\"|\"\""; //这个最好,不受转义符影响
//Exercise19.testUnitDoubleQuotePattern(doubleQuoteRegex4);
//Exercise19.testUnitDoubleQuoteReplace(doubleQuoteRegex5);
}
}